Audition技巧:半自动分切音频
目标
在做电子书时,我需要把几百个生字朗读音频逐字分切开,把课文朗读音频逐句分切开;或者获取每个分切位置的时间标签。总之是根据停顿静音进行分切的。此类要求可以通过Audition的自动标记功能实现。
步骤
自动标记
在“诊断”窗口,使用“标记音频-扫描-全部标记”,即可根据停顿处静音的长短,给音频分段打上标记。设置参数要根据音频情况调整。如果有背景音乐,可预先清除。
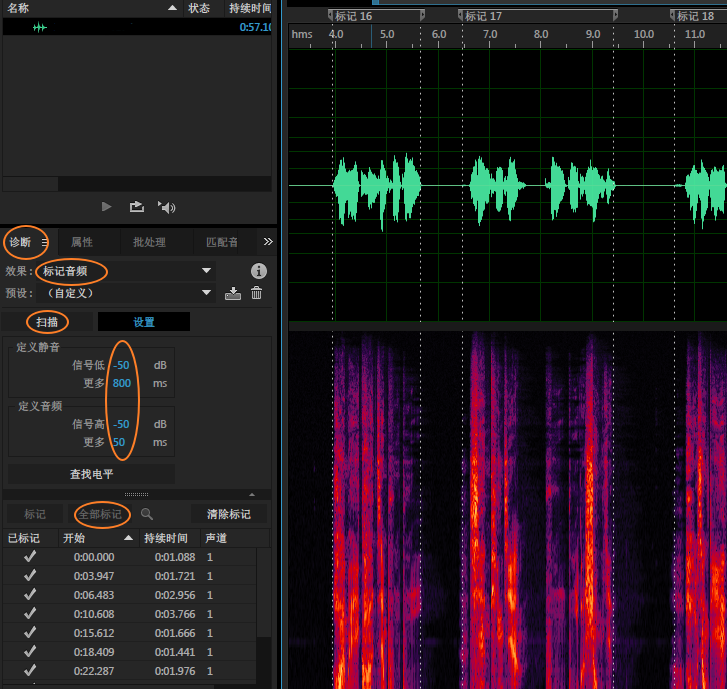
如果是低版本的Audition3,使用“编辑-自动标记-查找相位和标记”,设置则通过“编辑-自动标记-自动标记设置”。Audition3的标记无法导出,其标签信息可能不是UTF-8编码,在Audition6以后版本中打开后,中文无法显示。
调整标记
可以根据需要增加或删除一些标记。另外,自动标记首尾紧贴着声波,两个标记之间的静音没有括入。如果希望导出音频片段后能保持静音原状,则需把后一个标记的起始位置设置为前一个标记的结束位置(即把静音算到前一个标记范围内)。
- 为此,可以增加一个全长的标记(从0开始到音频末尾,并确保它是第一个标签);
- 然后导出所有标记到
.csv文件;
- 用安装了以下插件的Sublime Text(一个共享编辑器)自动处理;
- 把标记文件重新导入Audition;
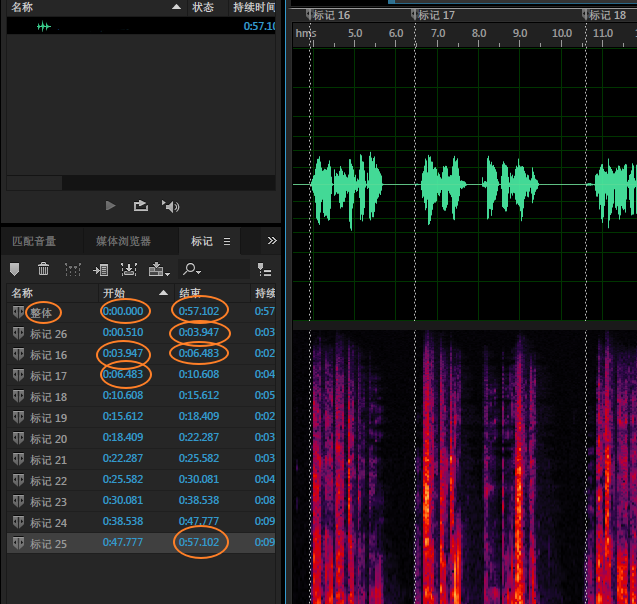
以上标记范围即可批量导出为音频文件。
sublime Text插件
用于调整音频文件时间标签,标签起始位置保持不变,结束位置调整为下一个起始位置(点标签也会如此调整为范围标签)。详情见代码注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61 | import sublime
import sublime_plugin
from datetime import datetime
# 调整音频文件时间标签,以便分段导出
# 把上一个标签的末尾,调整到下一个标签的开头处
# 第一行应是全长标签,第二列为0:00.000, 第三列有长度(不空不0)
# 只处理标签如下(1)以“标记”开头,其他的会被忽略
# 注意按起始顺序排列标签
# 例子:
# Name Start Duration Time Format Type Description
# 标记 01 0:00.000 0:56.850 decimal Cue
# 标记 02 0:01.109 0:01.529 decimal Cue 音频 标记
# 标记 03 0:04.382 0:00.902 decimal Cue 音频 标记
# 标记 04 0:07.048 0:02.257 decimal Cue 音频 标记
# …………
class WavLabelsModifyCommand(sublime_plugin.TextCommand):
def run(self, edit):
# 取得当前视图(即当前标签、当前缓冲)中的所有行范围
lines = self.view.lines(sublime.Region(0, self.view.size()))
# 全长
allDuration = ''
# 寻找全长标签
for line in lines:
times = self.view.substr(line).split('\t')
# 起始位置为0,并且有长度
if times[1] == '0:00.000' and times[2] != "" and times[2] != "0:00.000":
global allDuration
allDuration = times[2]
# print(times[1], times[2], allDuration)
break
end = allDuration
# 没有全长标签则告警
if end == "":
sublime.error_message("错误:没有全长标签!")
return
# 反向处理
for index, line in enumerate(reversed(lines)):
# 根据行头尾标签取得字符串,并据tab拆分
times = self.view.substr(line).split('\t')
if '标记' in times[0]:
global end
# print(end)
end = datetime.strptime(end, '%M:%S.%f')
begin = datetime.strptime(times[1], '%M:%S.%f')
# 校验是否为负值
if end < begin:
sublime.error_message("line " + str(-(index + 1)) + ":标签长度为负值!")
return
duration = end - begin
times[2] = str(duration)
# print(str(duration))
# 替换
self.view.replace(edit, line, '\t'.join(times))
end = times[1]
|