小工具:分割文本文件
目标、步骤
如果你想以特定格式的行(用正则表达式表示)为界,把一批文本文件分割成小片段,比如每章节或每卷一个文件,可以使用下面的Python脚本。你需要做:
- 保存脚本,后缀为
.py
- 根据你的实际情况更改脚本中的设置部分,尤其是:
- 用正则表达式表示文件分界标志行(作为下一个文件片段的首行)
- 在命令行中运行脚本(或看看右键菜单[打开方式]中有没有[Python])
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56 | """
reSplitFile.py
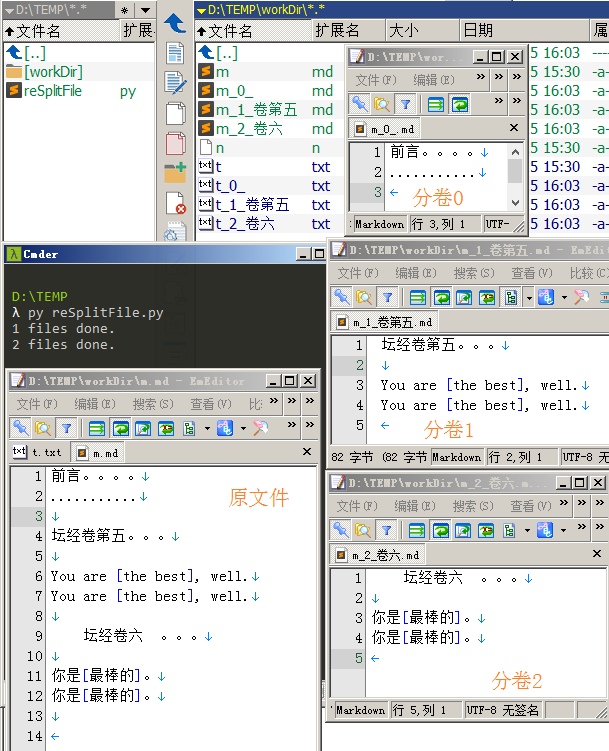
文件分割:
寻找指定路径下所有文本文件中的匹配行
把一个匹配行以下至下一匹配行之前的部分存为单独文件
新文件存在原文件相同的节点上,文件名
"""
import os, re
# 要处理的路径
DIR = "./workDir"
# 要处理的文本文件后缀列表
EXT = ['.txt', ".md"]
# 切分标记行(下一文件的首行)正则表达式,请按需设置
r = re.compile(r'^.{1,30}(卷第?[一二三四五六七八九十百千万零〇]+).{0,20}$')
# 是否在正则匹配前删除行中空白字符
DELET_SPACE_BEFORE_MATCH = True
fileNum = 1
for root, __, files in os.walk(DIR):
# 文件过滤(限定扩展名)
lesson_cut_file_list = [x for x in files if os.path.splitext(x)[1] in EXT]
for file in lesson_cut_file_list:
n = 0
outLines = []
chapter = ""
(fn, ex) = os.path.splitext(file)
fn += "_" + str(n) + "_" + chapter + ex
fileName = os.path.join(root, fn)
# 注意文件编码为utf-8(无签名)
with open(os.path.join(root, file), "r", encoding="utf-8") as f:
for line in f.readlines():
line = line.strip("\n")
# 先删除(忽略)行中空白字符
if DELET_SPACE_BEFORE_MATCH:
clean_line = re.sub(r"\s", "", line)
match_line = r.match(clean_line)
else:
match_line = r.match(line)
if match_line:
if outLines:
with open(fileName, "w", encoding="utf-8") as outFile:
outFile.write("\n".join(outLines))
outLines = [line]
chapter = match_line.group(1)
n += 1
(fn, ex) = os.path.splitext(file)
fn += "_" + str(n) + "_" + chapter + ex
fileName = os.path.join(root, fn)
else:
outLines.append(line)
if outLines:
with open(fileName, "w", encoding="utf-8") as outFile:
outFile.write("\n".join(outLines))
print(fileNum, "files done.")
fileNum += 1
|
效果