自制儿童识字语料库与分级字表
儿童识字,按核心目标和相应的教学形式,可以粗略地分为集中识字和分散识字两个大类。
所谓集中识字,就是在有限的时间,通过篇幅有限的专用文字材料,使儿童尽可能快,尽可能多地识字。它的核心目标是效率。
汉字多得很,学哪些,先学哪些、后学哪些,很有讲究。周有光先生说:
字数太多、字无定量,是汉字难学难用的主要原因。在难于减少字量的今天,可以用“分层使用”的方法,减少学习和使用的不便。……经验告诉我们,与其学多而不能用,不如学少而能用。汉字的使用频度是不平衡的,少数字常用,多数字罕用,这是汉字的“效用递减率”。把握这个规律,改进用字的方法,可以逐步减少用字数量。(周有光《21世纪的华语和华文》,载《群言》,2001(10))
汉字的效用不是均匀的,而是递减的,并且是非线性递减的,因此常用字非常集中。集中识字既然有时间和文字材料篇幅的限制,那么对字表进行分级,以便先学常用字,就显得特别重要。先学效用高的常用字,后学效用低的不常用字,这样孩子才能更快地开始阅读,才能更快获得成就感。
那么现在的问题是,字表怎么分级?
通常的思路是先制备儿童分级读物语料库,然后分级统计字频;也可以同时统计词频,考虑词的效用问题,以及字的构词能力问题;还可以考虑字词在各篇目中的分部情况。 当然,从形体结构上看,一个汉字可以由其他汉字拼合而成,因此汉字的构字能力也值得考虑。
我多年跟踪此类语料库的信息,得到如下一些线索。(本人并非专家,所知有限,谨供参考。您如果有更好的发现,恳请告诉我。)
比较重要的汉语母语学习类语料库#
- 厦门大学国家语言资源检测与研究教育教材中心语料库之中小学语文教材语料库,包括人教社、苏教社、语文社、北师大社4家的小学语文和初中语文共8套教材(语文社小语为S版),词记录数1,289,898,字符数1,834,150。这条小新标明原载于厦门大学官网,但我没有查到。细节可与官网上的《第二届教育教材研讨会在福建武夷山召开》这条信息相印证。另,在厦门大学苏新春教授主编的《<义务教育常用词表(草案)>说明》(2019)中,说到使用了“小学语文教材语料库(500万字)”。
- 北京师范大学的“中学语文教材语料库”(1983),106.8万字。我没有查到公开发布的成果。
- 台湾教育当局的《國小學童常用字詞調查報告書》(2002),统计的是课内外读物,样本量为120多万字。有详尽的统计、分析,并全部发在网上。
- “中小学生课外读物语料库”,统计了100多万字的中小学生课外读物。没有公开详细统计数据。(见于龙、陶本一《基于语料库的小学语文教材用字研究》,载《语言文字应用》2010.2(1))
- 上海现行版语文教材(一至五年级)语料库。没有公开详细统计数据。(出处同上)
上面这些跟儿童识字相关度比较高。它们的问题是没有分级,甚至中小学混在一起,或者仅有中学段;或者样本量不多;台湾的的用语用字跟大陆会有不少差别。
另外,我多年似乎听闻,我的母校北师大有此类语料库,但是多方打听也没有线索。我看王宁先生等人的相关论文似乎也没有提到。
幼儿日常会话跟踪语料库#
- 南京师范大学李葆嘉等所建汉语幼儿(2~6岁)日常会话跟踪语料库,原载李葆嘉、王彤等《幼儿语言的成长:常用词汇语义系统建构》,科学出版社,2021
-
“汉语幼儿日常会话跟踪语料库”从2005年启动,到2015年告一段落。录音语料库总时长35442分钟,包括18个子库(两岁幼儿3个、三岁幼儿4个;四岁幼儿4个、五岁幼儿5个和群体1个、六岁幼儿1个)。其中已转写的(时长30709分钟)建成11个文本语料库,约360万字(纯幼儿语料145万字)。尚未转写的7个录音语料库(时长4733分钟),可转写约56万字。全部转写后,预计总规模约420万字(纯幼儿语料165万)。
-
根据现有语料统计和提炼,汉语幼儿常用词汇量大体如下:两岁段628个、三岁段1376个(递增748个)、四岁段1847个(递增471个)、五岁段2227个(递增380个)、六岁段2938个(递增711个)。
-
根据所采集幼儿语料(城市文化背景、父母大学毕业、家庭氛围良好;绝大部分是女孩,喜欢说话和录音;父母有耐心,对通过录音保留幼儿语言生活感兴趣)的统计分析,当前汉语幼儿词汇发展水平比其父母(20世纪70年代出生)幼儿时期的状况提前约半年。如今两岁段幼儿的词汇量(13~24个月DD9.6万纯幼儿语料中,共出现词语2830个,频率5次以上的约684个,频率10次以上的约436个),相当于过去两岁半幼儿的词汇水平。如今三岁段幼儿的词汇量(26~36个月XX 18万纯幼儿语料中,共出现词语3413个,频率5次以上的约1593个,频率10次以上的约1046个),相当于过去三岁半幼儿的词汇水平。
-
比较新的社会通用语料库成果#
现在有多种多样的语料库。社会通用语料库,比较新、规模比较大,而且普通人能接触到字频、词频等成果的有:
- 国家语委国家语言资源监测与研究中心2005—2015年的《中国语言生活状况报告》,2016—2018年的《中国语言文字事业发展状况》。(只有纸质出版物)
- 台湾教育当局1995—1997连续三年的《常用語詞調查報告》,样本量在100—150万字之间。在线发布了全部成果。
这些语料的用字跟儿童用字差别比较大,参考价值不高。
顺便说一下,有一套现在很流行的幼儿识字教材(我女儿也在用),它参考的是1970年代的社会通用字频统计数据,这是很不合适的。详见《汉字有多多》。
我自制语料库的思路#
我2017年从语文出版社离之后,根据网络资料和手头资料整理了17套中小学语文教材和两套同步读物,其中多数为新课标实验教材,而且主要是小学教材。有些教材内容不全,还有缺乏精校等其他一些问题。
这些材料的好处是:
- 语言规范。小学语文教材都是逐字逐句修改过的。这样一来,这些课文可以保证语言规范、字词难易适度。(当然,文风上可能个人特色变少了,这是题外话。)配套读物的文字质量会稍低一些。
- 分级明确。教材和配套读物都经过明确分级,字词和内容的难度、篇幅的长度都是考虑的因素。(根据本人13年编写、编辑小学语文教材的经验,小学低、中、高三段之间的梯度是非常明显的,每段内部两个年级之间的梯度较小,尤其是在中、高段;除一年级外,每年级两册之间的梯度可以忽略。)
- 内容多样、均衡。根据课标编写、集体编写、长期打磨而成的小学语文教材和配套读物,可能没有特色,但是内容是多样的,均衡的。
所以,目前我认为小学语文教材和配套读本是最好的识字语料,能很好地反映孩子将来可能碰到的实际读物的用字、用词情况。
最近从一家做在线中小学作业辅助的知名公司了解到,他们的语料库也是我这个思路。他们只收录了八九套使用量较大的新课标实验教材,也没有收录与教材配套的同步阅读材料(此类材料的文字量往往是教材的四五倍);不过,他们的材料可能经过人工精校,在齐全、准确上会做得比较好。
我的语料库统计结果#
我对我的语料库进行了用字、用词的统计。本文只介绍字频的情况。
先看字的累积覆盖率,这意味着学会多少个字可以覆盖文章用字的百分数是多少:
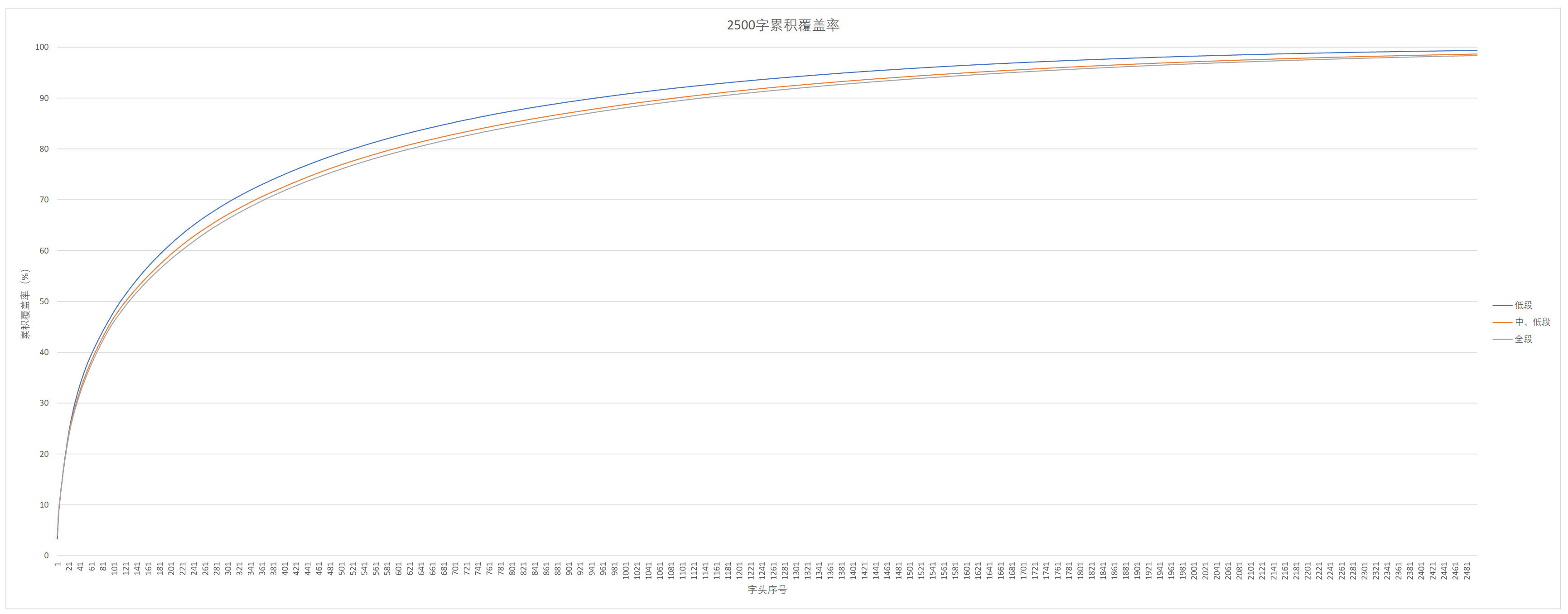
上表直观地反映出语料库中汉字效用递减的情况。
我的语料库是分册的,又按课程标准以及教材编写和教学的惯例把小学分成低段(一二年级),低、中段(一到四年级)、全段,分别进行统计。
| 分段 | 样本量(万字) | 用字(种) |
|---|---|---|
| 低段 | 47.2 | 3569 |
| 低、中段 | 180.5 | 4697 |
| 全段 | 366.3 | 5308 |
用到表外字1821个。字种仅仅根据计算机字符码表来区分,由于没有人工精校,可能混入了一些难字,所以“用字(种)”可能有出入。
《义务教育语文课程常用字表》中的13个字始终没有出现,它们是:
阐畴痘矾肛汞癸妓馏赂壬讼赃
有趣的是,在这些字里面,“赂讼赃痘肛妓”在成人言语中很常用,共同特点是都带有负面情感。这也许反映了小学语文教材的“洁癖”倾向。
本人编教材时,曾为了在低段挑选“屎尿屁”这几个字进入生字表,跟领导费了很多口舌。领导是担心学生在课堂学这些字会笑场,课后想起这些字会说“脏话”,所以把这些字押后再说。
说到“洁癖”问题,再补充一个小故事。我们的教材始终没有使用“林阴道”这个词形,而是按《现代汉语词典》的一贯坚持,用“林荫道”。而按照当时仍有效的《普通话异读词审音表》(1985,国家强制标准),“荫”只有yin4这个读音和意思,没有yin1这个音和意思。等到2013年《通用规范汉字表》发布,荫又有了yin1的身份。
我自制字表的思路#
从上图可以看出来,字表分级的意义是很大的。另外,低段汉字的效用变化跟中高段差别较大,因此低段用字情况需要特别对待;而后两段之间差别不大。
根据统计得到的字频数据和识字的实际需要,我把字表分成a、b、c、d、e五级。
a级字表668字#
a级字表的目标是,语料覆盖率在80%左右,同时包含《义务教育语文课程标准·识字、写字教学基本字表》(300字)。
根据低段字频进行排序(特意照顾低段用字情况),提取前626字。此时,这些字对三段材料的覆盖率分别是83.29%,80.02%,78.40%。
然后再加上《义务教育语文课程标准·识字、写字教学基本字表》中载明但尚未纳入的字(42字),这样就变成668字。此时对三段材料的覆盖率分别是84.04%,80.87%,79.28%。
b级字表1101字(新增433字)#
b级字表的目标是,语料覆盖率在90%左右。
按中、低段字频排序,提取前1101字(比a表增加433字),此时对三段材料的覆盖率分别是91.35%,90.09%,89.25%。
c级字表1600字(新增499字)#
c级字表的目标是1600字,与《义务教育语文课程标准》规定的低段识字量一致。
此时按全段字频排序,取前1600字(比b表增加499字),对三段语料的覆盖率分别是95.33%,94.78%,94.45%。
d级字表2500(新增900字)#
d级字表的目标是2500字,与《义务教育语文课程标准》规定的中、低段累计识字量一致。
此时按全段字频排序,取前2500字(比c表增加900字),对三段语料的覆盖率分别是98.85%,98.55%,98.35%。
此表与《义务教育语文课程常用字表》第一表(2500字)不完全一致,有39字是后表没有的:
佚咚噢嬉嘟眺嗯噜攒咯呱嘎嗒喃漉轼柯蘸淙蚱栩蝈莎嫦黛喔茨陀娲詹佗羿晏吒桓瑜俑鲧蔺
《义务教育语文课程常用字表》即《通用规范汉字表》的“一级字表”,虽然有意为基础教育做特别考虑,但我估计还是主要针对社会一本用字情况(我没有看到具体的研制情况,比如有没有中小学阅读语料数据的支持),它跟教材实际用字有些差异是很正常的。
有趣的是,从上述39个字就能看出小学语文用字跟一般社会用字之间的某些区别。比如在上面这些字里,
- 有个别难字,比如“佚嬉眺攒漉栩”等,其中有些字见于某些小学语文常用词语中,如“攒钱”“眺望”“栩栩如生”,后两个是比较“文”的词;
- 很多是拟声词用字,比如“咚噢嘟嗯噜咯呱嘎嗒喃淙喔”,中小学语文常用拟声词;
- 有些字跟特定的常用课文有关,比如《嫦娥奔月》的“嫦”,《女娲补天》的“娲”,《詹天佑》的“詹”,《华佗》《军神》中的“佗”,《后羿射日》的“羿”,《晏子使楚》的“晏”,《哪吒闹海》的“吒”,《赤壁之战》用的“瑜”,《秦兵马俑》的“俑”,《鲧禹治水》/《大禹治水》的“鲧”,《将相和》用的“蔺”;
- 有不少是人名用字,除上条提到的,还有“苏轼”的“轼”,外国人译名常用字“莎黛茨”;
- 还有动物名称用字,如“蚂蚱”的“蚱”,“蝈蝈”的“蝈”,这两种虫子在小学课本里很常见,南方人了解“蚂蚱”,北方人爱玩“蝈蝈”。
补充说一点,很多动植物名称用字在低段的字频要比在中高段的字频高很多。这大概跟小学语文文学化、诗意化有关。低段课文有很多韵文、拟人童话,都包含动植物角色。这也不奇怪,孔子就说过学习诗歌最基本的意义之一就是“多识鸟兽草木之名”。
e级字表3539字(新增1039字)#
e级字表的目标是囊括《义务教育语文课程常用字表》的3500字,以及此前出现过的超表字39字。
此时对三段语料的覆盖率分别为:99.58%,99.49%,99.44%。
数据汇总#
现把上面的数据汇总如下(覆盖率是百分数),方便对比:
| 字表 级别 | 字数 | 新增 字数 | 低段 覆盖率 | 低、中段 覆盖率 | 全段 覆盖率 | 平均 覆盖率 | 新增 平均覆盖率 |
|---|---|---|---|---|---|---|---|
| a | 668 | 0 | 84.04 | 80.87 | 79.28 | 81.40 | 81.40 |
| b | 1101 | 433 | 91.35 | 90.09 | 89.25 | 90.23 | 8.83 |
| c | 1600 | 499 | 95.33 | 94.78 | 94.45 | 94.85 | 4.62 |
| d | 2500 | 900 | 98.85 | 98.55 | 98.35 | 98.58 | 3.73 |
| e | 3539 | 1039 | 99.58 | 99.49 | 99.44 | 99.50 | 0.92 |
这里可以看出各级别字表的效用差别,也就是识认效益差别。
我没有对字表进行手工调整(比如保证某些紧密相关的字如“蝴、蝶”在同一个级别中),因为我一般是通过程序计算来使用这些数据的,如果要调整,也会等到最终环节才进行。
字表见《自制儿童识字分级字表》